Künstliche Intelligenz in der Schule – Potentiale und Risiken
Künstliche Intelligenz und Schule, eine noch eher ungewöhnliche Kombination. Bisher galt: Viel Kreide, wenig Touchscreen. Doch dieses Bild ändert sich. Glasfaser, interaktive Whiteboards und Schulcloud kommen in den Schulen an. Digitalpakt sei Dank. Breitband-Internet und moderne Hardware öffnen die Türen für künstliche Intelligenz im Klassenzimmer. Welche Potentiale bringt diese Technologie mit sich? Die gute Nachricht vorab: Es gibt zahlreiche datenschutzkonforme Anwendungsbeispiele.
Wer sich nicht für den theoretischen Hintergrund künstlicher Intelligenz und die Herleitung der Potentiale interessiert, kann hier direkt zu den Anwendungsbeispielen springen.
Viele Bedürfnisse – wenig Personal
Die Heterogenität in Klassen ist groß, individuelle Förderung die Lösung. Doch wie sollen Lehrkräfte auf die unterschiedlichen Fragen und Bedürfnisse von 20 oder 30 Schülern und Schülerinnen gleichzeitig eingehen? Die von den Bildungsministerien geforderte Binnendifferenzierung stellt Lehrerinnen und Lehrer vor riesige Herausforderungen.
Bereits 1984 forschte der Psychologe und Erziehungswissenschaftler Benjamin Bloom zum optimalen Betreuungsverhältnis und kam zu dem Ergebnis:
Lernende, die 1-zu-1 von einem Tutor betreut wurden, erzielten im Durchschnitt vergleichbare Ergebnisse wie die besten zwei Prozent in einem 1-zu-30-Verhältnis.
Brauchen wir also mehr Lehrpersonal? Definitiv: Frank Kirchner, Chef des DFKI Bremen, prognostiziert eine notwendige Steigerung um das Zehnfache für das deutsche Bildungssystem und rückt die bildungspolitische Brisanz in den Fokus – doch wie lässt sich das finanzieren und wer bildet das dringend benötigte Fachpersonal aus? Gleichzeitig sinkt die Zahl der Lehrkräfte von Jahr und zu Jahr und die Situation verschärft sich.
Die Methoden, mit denen wir unsere Kinder unterrichten, gehen mit der Zeit – doch wie sieht der verantwortungsvolle und verhältnismäßige Einsatz moderner Technologie im Klassenzimmer aus?
Software als virtueller Tutor
Eine Metastudie der TU München im Auftrag der Kultusministerkonferenz kommt zu dem Schluss, dass intelligente Tutorensysteme die größte positive Wirkung auf die Lernergebnisse in MINT-Fächern haben. Untersucht wurden 80 Einzelstudien zum Einsatz von digitalen Medien in der Schule. Dabei wurden nicht nur Erkenntnisse darüber gewonnen, wie diese Medien im Unterricht eingesetzt werden sollten, sondern auch, welche Typen digitaler Medien den größten Erfolg versprechen. Intelligente Tutorensysteme stechen dabei positiv hervor.
Intelligente tutorielle Systeme wie bettermarks begleiten und unterstützen die Schülerinnen und Schüler beim täglichen Üben und simulieren die besonders lernwirksame 1:1-Betreuung – und zwar im Moment der Aufgabenbearbeitung! Personenbezogene Daten werden zum Lernen nicht benötigt. bettermarks arbeitet datenschutzkonform mit Pseudonymen.
Ohne Lernsoftware machen die Schülerinnen und Schüler Rechenübungen auf Arbeitsblättern, in Aufgabenheften oder Schulbüchern. Die Aufgaben werden im besten Fall erst am kommenden Tag korrigiert. Die Kinder müssen die Transferleistung erbringen, die Lösungen miteinander zu vergleichen und Abweichungen nachzuvollziehen. Ratlosigkeit und Lernfrustration sind die Folge. Viel schlimmer: Fehlvorstellungen verfestigen sich, wenn sie beim Üben ohne Rückmeldung immer wieder und wieder wiederholt werden.
Die Rückmeldung »das ist falsch« ist die qualitativ schlechteste Rückmeldung. Jedoch definitiv hilfreicher als gar keine Rückmeldung. Am hilfreichsten sind Rückmeldungen, wenn sie auf erkannte Fehlvorstellungen reagieren.
Grundlegend für den Lernerfolg ist ein anwendungsbasiertes Lernsystem. Statt eines Zufallstreffers bei Multiple-Choice-Fragen wenden die Kinder bei bettermarks ihre mathematischen Kompetenzen an. Beispielsweise beim Zeichnen einer Funktion: Werden die Achsen im Koordinatensystem beim Setzen eines Punktes vertauscht, bekommen die Lernenden ein präzises Echtzeit-Feedback und somit die Möglichkeit, den Fehler zu erkennen, zu verstehen und zu korrigieren – ohne dass er sich verfestigt. Diese schrittweisen Hilfen und Rückmeldungen heißen »Scaffolding« (engl. für Hilfsgerüst).
Intelligente Rückmeldungen in einem ITS (intelligentes Tutorsystem)
In einem ITS gibt es Mikro-Adaptivität (»inner loop«) und Makro-Adaptivität (»outer loop«). Alle Rückmeldungen, die sich direkt auf eine Eingabe beziehen, gehören zu Mikro-Adaptivität. Reaktionen des Systems, die sich aus einer Summe von Eingaben ergeben, werden der Makro-Adaptivität zugeordnet, zum Beispiel die Erkennung von Wissenslücken. Die technischen Voraussetzungen für adaptive Rückmeldungen sind hier beschrieben: Aus Fehlern lernen – Das Konzept hinter bettermarks.
Übrigens: Eine künstliche Intelligenz kann nicht ohne Weiteres inhaltlich-didaktische Rückmeldungen erzeugen. Diese sind initial immer das Ergebnis menschlicher Intelligenz.
Künstliche Intelligenz und Ethik – Ein Blick nach China
China plant im Hinblick auf die Digitalisierung der Schulen, seine Lehrmethodik bis 2030 umzustellen und sich als das technologische Innovationszentrum weltweit zu etablieren. Hierfür werden große Mengen von Daten gesammelt – die Big Data. Landesweit laufen bereits Projekte in vielfältiger Ausprägung. Eine Grundschule in Hangzhou testet an den Kindern Kopfbänder, die Hirnsignale hinsichtlich der Aufmerksamkeitsspanne messen können.
Andernorts erfassen Kameras minutiös die Gesichtsausdrücke der Kinder und kategorisieren sie in unterschiedliche Farbskalen: Grün folgt aufmerksam dem Unterricht, Orange nähert sich einem Dämmerzustand oder tuschelt mit dem Nachbarn. Rot beteiligt sich innerlich nicht mehr am Unterrichtsgeschehen. Eine Aufnahme pro Sekunde, 3600 pro Stunde.
Der Geschäftsführer einer der führenden Unternehmen im Bereich Digitalisierung an Schulen, Zhang Haopeng, sieht in dieser Methode eine echte Chance, die Schülerinnen und Schüler gleichbehandeln und unmittelbar auf ihre Bedürfnisse eingehen zu können. Er äußerte sich dazu in der FAZ im Mai 2019: »Lehrer konzentrieren sich in der Regel auf zwei Arten von Schülerinnen und Schülern: die Besten und die Störer. Diese Ungerechtigkeit gegenüber den anderen Kindern will das System beheben.«
Die Lehrkraft habe so die Möglichkeit, rechtzeitig mit passender Methodik zu reagieren und die einzelnen Kinder optimal zu betreuen. Die Leistung der Lehrkraft wird mitunter durch Stimmerkennung ermittelt, zudem der Anteil des Frontalunterrichts evaluiert. Alle Daten stehen der Schulleitung übersichtlich zur Verfügung. Dadurch biete sich die Option, zu intervenieren und den Lehrkräften Alternativvorschläge für ihren Unterricht anzubieten.
Künstliche Intelligenz für mehr »Chancengleichheit« – glücklicherweise ist der chinesische Ansatz in Europa undenkbar.
Künstliche Intelligenz funktioniert auch ohne personenbezogenen Daten
Mit bettermarks haben wir ein didaktisches Geometrie- und Algebrasystem entwickelt, eine Art Betriebssystem für Mathematik. Jede Aufgabe und jeder Aufgabentyp ist wie eine kleine App. Diese verwendet die Eingabewerkzeuge, Darstellungsformen und Logiken des »Betriebssystems«, um mit dem Schüler oder der Schülerin zu interagieren. Die Analyse der Eingaben, das Erkennen von Fehlvorstellungen und die dazu passende Rückmeldung sind Voraussetzung für einen gelingenden Lernprozess. Eine künstlichen Intelligenz kann diese Rückmeldungen nicht erfinden. Denn sie kann keinerlei Fehlvorstellungen eigenständig ermessen.
Die Fehler-Rückmeldungen basieren bei bettermarks auf menschlicher Intelligenz: 2.800 Erkennungsmuster verschiedener Fehlvorstellungen wurden von den Autorinnen und Autoren akribisch hinterlegt. Beispielsweise erhalten Lernende das unmittelbare Feedback: »Du hast das Dreieck richtig konstruiert, aber kontrolliere noch die Beschriftung der Punkte.« Bislang nicht bekannte Fehleingaben kann bettermarks anonymisiert auswerten und als neue Fehlererkennungsmuster programmieren. Das System wird also durch didaktische Expertise der Autorinnen und Autoren intelligenter. Eine KI könnte dies nicht leisten.
Ein weiterer Vorteil ist die geringe Datenmenge, die bettermarks für seine Funktionalität benötigt. Einzig die getätigten Lösungsversuche sind notwendig, um die Lernenden optimal in ihrem individuellen Lernprozess zu unterstützen. Personenbezogene Daten (wie beispielweise Klarnamen oder E-Mail-Adressen) werden beim Anlegen einer Klasse durch eine Lehrkraft nicht hinterlegt. Stattdessen kommen Pseudonyme zum Einsatz. Wird bettermarks über ein externes Learning Management System wie die »HPI Schulcloud«, »Moodle«, »Univention« oder »It’s Learning« genutzt, sind Nutzungs- und Nutzerdaten sogar physikalisch getrennt und aus Sicht von bettermarks faktisch anonymisiert.
Wenn eine künstliche Intelligenz keine inhaltlich-didaktische Rückmeldungen erfinden kann, wo liegt dann das Potenzial von künstlicher Intelligenz im Lernkontext?
Was ist künstliche Intelligenz?
Künstliche Intelligenz (KI) oder auch »artifical intelligence« (AI) meint im Wortsinn eine selbstständig denkende Instanz, die nicht menschlich, sondern eben künstlich bzw. maschinell agiert. »Intelligenz« kennzeichnet neuronale Prozesse im menschlichen Gehirn, die von außen betrachtet nicht nachvollziehbar sind. Somit basiert eine künstliche Intelligenz auf maschinell erzeugten neuronalen Netzen.
Die Faszination für diesen mit unserer eigenen Vorstellungskraft nicht überprüfbaren Vorgang hat Geschichte. Schon die Menschen im Mittelalter kamen auf die Idee, sich einen künstlichen Sparringspartner zu kreieren. Homunkulus, der künstliche Mensch, der unter Zischen und Brodeln in einer Phiole erzeugt wurde, fand in Goethes Faust II literarische Umsetzung.
Technisch geht die Evolution von KI bis in das Jahr 1769 zurück. Zu dieser Zeit gelang dem österreichischen Erfinder und Mechaniker Wolfgang von Kempelen der Bau eines Schachautomaten, dessen »getürkte« Funktionsweise erst nach vielen Jahren gelüftet wurde: In einem Holzkasten unterhalb des Schachbretts saß für Außenstehende nicht sichtbar ein Mensch, der die geschickten Schachzüge vollführte. Die künstliche Intelligenz beschränkte sich hier also noch auf mechanische Tricks.
1947 warf der Logiker Alan Turing die Frage auf: »Kann eine Maschine denken?«. John McCarthy formulierte zeitgleich das »Ziel der KI ist es, Maschinen zu entwickeln, die sich verhalten, als verfügten sie über Intelligenz«.
Er prophezeite für die nahe Zukunft einen Schachcomputer, der tatsächlich eigenständige Züge vollführen würde – 1996 schlug »Deep Blue« den damals amtierenden Schachweltmeister Garri Kasparow. Schnellere Prozessoren und verbesserte Algorithmen beschleunigen den Fortschritt und die Anwendungsfelder.
Machine Learning – die selbstständig lernende Maschine
Ein Teilbereich von künstlicher Intelligenz ist das »Machine Learning«, das sich ab den 1980er Jahren etablierte. Die Forschungsbereiche, innerhalb derer eine Maschine lernt, gliedern sich in drei Kategorien:
- das überwachte Lernen (Supervised Learning),
- das unüberwachte Lernen (Unsupervised Learning) und
- das bestärkende Lernen (Reinforcement Learning).
Basis aller Lernfelder ist ein regelbasierter Algorithmus.

Supervised Learning
Beim »supervised learning« wird der Lernprozess durch menschliche Vorgaben gesteuert und innerhalb der Eigenschaften des agierenden, technischen Systems ergänzt. Das Lernziel, das die Maschine erreichen soll, wird klar vorgegeben. So konnte »DeepBlue« zwar exzellent Schach spielen, wäre jedoch bei der Lösung eines Sudokus gescheitert.
Uns begegnet überwachtes Lernen heute beispielsweise in Form eines Recommender-Algorithmus – ein empfehlendes System, das stetig dazulernt. Statt fixer Empfehlungskritierien wird ein generischer Algorithmus mit Daten gefüttert.
Beispiel: Amazon & Netflix
Die Produktsuche bei »Amazon« oder gewählte Filmgenres auf dem Streamingportal »Netflix« dienen der Maschine als neue Impulse. Sie erkennt die zuvor gelabelte Produkte. Der Algorithmus empfiehlt sogleich Alternativen und passt sich individuell an das Nutzerverhalten an.
Unsupervised Learning
Während des Lernprozesses im »Unsupervised Learning« ist es Aufgabe des Computers, Muster und Strukturen aus einer Eingabe von unbenannten Objekten zu erkennen und zuzuordnen. Aus einer unsortierten Bildersammlung von Hunden und Katzen kann er beispielsweise Gruppierungen bilden, sogenannte Cluster. Diese technische Fähigkeit ist ein entscheidender Fortschritt für die Medizin. So ist es möglich, Krebserkrankungen zügiger und mit einer zuverlässigeren Trefferquote zu diagnostizieren. Der Computer erhält eine gigantische Datenmenge von MRT(Magnetresonanztomografie)-Bildern, scannt, vergleicht und clustert schließlich die Größe, Beschaffenheit und Auffälligkeiten von Tumoren. Mit einer hohen Wahrscheinlichkeit (von bis zu 99%) und in Bruchteilen von Sekunden bietet die Maschine dem behandelnden Arzt bzw. der Ärztin für die Bewertung von eher einfacheren Krankheitsbildern eine treffsichere Diagnose an. In Folge kann das medizinische Fachpersonal die Aufmerksamkeit auf weitaus kompliziertere Krankheitsbilder richten.
Beispiel: Chatbots
Unüberwachtes Lernen gelingt auch in der App Replika , die Freundschaften simuliert – ein vermeintlich willkommenes Mittel, um nicht nur in Coronazeiten gefühlter Einsamkeit entgegenzuwirken.
In gleicher Weise, aber von zwiespältiger Tragweite, agieren Chatbots. So birgt das Potenzial des unüberwachten Lernens gleichermaßen die Gefahr, kreativ zu werden – aus den gebildeten Clustern ist die Maschine fähig, eigenständige Verknüpfungen herzustellen. In jüngerer Zeit mussten wiederholt die Anbieter solcher Bots ihren Betrieb einstellen, weil sie auf Basis von leichtfertig verwendeten Kundendaten trainiert wurden und böswillige Nutzer die Möglichkeit entdeckten, sie zu diskriminierenden Botschaften zu bewegen.
Allen Irrtümern und Missverständnissen vorbehalten – auch einer Maschine kann mal ein Fehler unterlaufen. Diese Form des maschinellen Lernens liefert dennoch kreative Ideen, auf die ein Mensch vielleicht nicht gekommen wäre.
Reinforcement Learning
Im dritten Teilbereich »Reinforcement Learning« wird das Lernen der Maschine bestärkt oder auch belohnt. Programmierer speisen wiederholt Impulse in die Algorithmen ein, um das lernende System in seiner Handlung zu bestärken bzw. die Funktionsweise zu beeinflussen und zu optimieren. Ohne zuvor festgelegte Zielvorgaben wird dem Computer ein positiver oder negativer Erfolg signalisiert. Dadurch lernt die Maschine, Prozesse zu forcieren bzw. zu unterlassen. Je häufiger sie einen Lernprozess durchläuft, desto präziser wird das Lernergebnis.
Beispiel: Einparkhilfe
Ein Beispiel ist der Einparkassistent: Dank der Objekterkennung kann das System dem Fahrer beim Einparken behilflich sein und optimiert die Anzahl der benötigen Züge sowie die Dauer des Vorgangs, ohne dabei zu stark zu beschleunigen.
Deep Learning – hallo, künstliche Intelligenz!
Deep Learning ist ein Teilbereich des Machine Learnings und findet als jüngste Disziplin im Bereich KI erst seit Anfang des 21. Jahrhunderts Umsetzung. Die maschinelle Systematik ist deutlich vielschichtiger und funktioniert folgendermaßen: Die Input-Neuronen nehmen Signale aus der Außenwelt auf und übermitteln sie an die Hidden-Neuronen, die die empfangenen Daten verarbeiten. Hier findet der Lernprozess statt – während ihres Verarbeitungsprozesses verdichten sich die Daten zu einem neuronalen Netzwerk oder auch Schichten, die Layer. Je mehr Hidden-Layer in einem Netzwerk vorhanden sind, desto tiefer findet ein Lernprozess statt – das »Deep Learning«. Mit Hilfe der generierten Information an die Output-Neuronen kann das System intelligente Entscheidungen treffen.
Beispiele: Gesichtserkennung und Routenberechnung
Ein Beispiel für Deep Learning ist Gesichtserkennung – je umfangreicher die Daten sind, die das System sammelt, desto feiner und präziser kann die Software Gesichter erkennen. Auch autonomes Fahren gelingt, weil der Computer durch wiederholte Tätigkeit neue Daten sammelt und seinen Lernprozess neuronal vertieft. Beispielsweise, wenn entlang einer Busstrecke eine Baustelle eingerichtet wurde.
Die Funktionsweise des Deep Learnings hat dem menschlichen Gehirn voraus, dass es eine ungleich größere Zahl an Daten und Informationen erfassen und in maximaler Geschwindigkeit ohne Ermüdung verarbeiten kann.
Wer KI in der Schule verantwortungsvoll anwendet, reduziert die gesammelten Daten auf das nötige Minimum.
KI & Lernpfade – Welche Daten werden benötigt?
Häufig wird das Stichwort »Lernpfade« mit künstlicher Intelligenz in Verbindung gebracht, gar synonym verwendet. Hier gilt es zu unterscheiden: denn technisch gesehen ist ein regelbasiertes Algorithmen-System bereits in der Lage, aus der Summe der getätigten Eingaben und auf geringer Datenbasis Lernpfade zu zeichnen, ohne dafür ein künstliches neuronales Netzwerk bilden zu müssen. Beim Üben mit bettermarks erhalten Schülerinnen und Schüler das Angebot, ihre Wissenslücken zu schließen, um somit an den Lehrstoff anzuknüpfen. Zur Prüfungsvorbereitung kann ein Einstufungstest Klarheit über den aktuellen Lernstand schaffen und passende Inhalte zum zielgerichteten Üben anbieten.
Verarbeitet eine Software zusätzliche Informationen, um ein neuronales Netzwerk als Basis einer künstlichen Intelligenz bilden zu können, stellt das für die Lernenden ein höheres Risiko dar. Die KI könnte Zusammenhänge erkennen, die bei der Programmierung im Vorfeld nicht bedacht wurden. Es könnten ungewollte oder sogar kontraproduktive Effekte entstehen.
Beispiel: Personalsoftware
Vor einiger Zeit trainierte ein Online-Versandriese einen Algorithmus für seine Bewerberauswahl. Allerdings bevorzugte die Software männliche Bewerber und grenzte weibliche Bewerberinnen aus. Dieser Effekt ergab sich aus der Art und Weise der Programmierung. Die Software wurde schließlich aus Gründen von Diskriminierung eingestellt.
Beispiel: Autonomes Fahren
Richard David Precht beschreibt in seinem Buch »Künstliche Intelligenz und der Sinn des Lebens« ein Szenario im Bereich autonomes Fahren: Messe- oder Firmengelände und auch Schienenleitsysteme von Straßen- und U-Bahnen sind ein regelbasiertes Umfeld, in dem Fahrzeuge ohne weiteres selbstständig fahren können. Das unkontrollierte Verkehrschaos einer Großstadt eignet sich jedoch nur bedingt für selbstfahrende Autos, da die Umgebung zu komplex ist, als dass sich ein System auf Basis von KI darin zurechtfinden könnte. Menschen wissen, dass selbstfahrende Autos stoppen würden, wenn sie bei Rot die Ampel überqueren. Die notwendige Folge wäre eine gesteigerte Verkehrsüberwachung durch beispielsweise Gesichtserkennung: Menschliche Störer würden so identifiziert und mit Strafe und Bußgeld belegt werden. Wäre eine ständige Überwachung der Preis, den wir als Bürgerinnen und Bürger bereit wären zu zahlen … für autonomes Fahren als bedürfnisorientierte Erleichterung? KI könne sich nur dann durchsetzen, so Precht, sofern eine absolute Notwendigkeit bestehe.
Bettermarks generiert bereits den wertvollsten Datensatz für einen gelingenden Lernprozess: die maschinell verarbeitbare Fehlvorstellung der Lernenden. Das Sammeln von zusätzlichen Datensätzen über die Aufmerksamkeit der Schülerinnen und Schüler bzw. die Messung von Hirnaktivitäten, wie es das Beispiel China zeigt, bietet keine unmittelbare Lernunterstützung und ist zudem aus ethischer Sicht ein absolutes No-Go.
Künstliche Intelligenz: Anwendungsbeispiele in der Schule
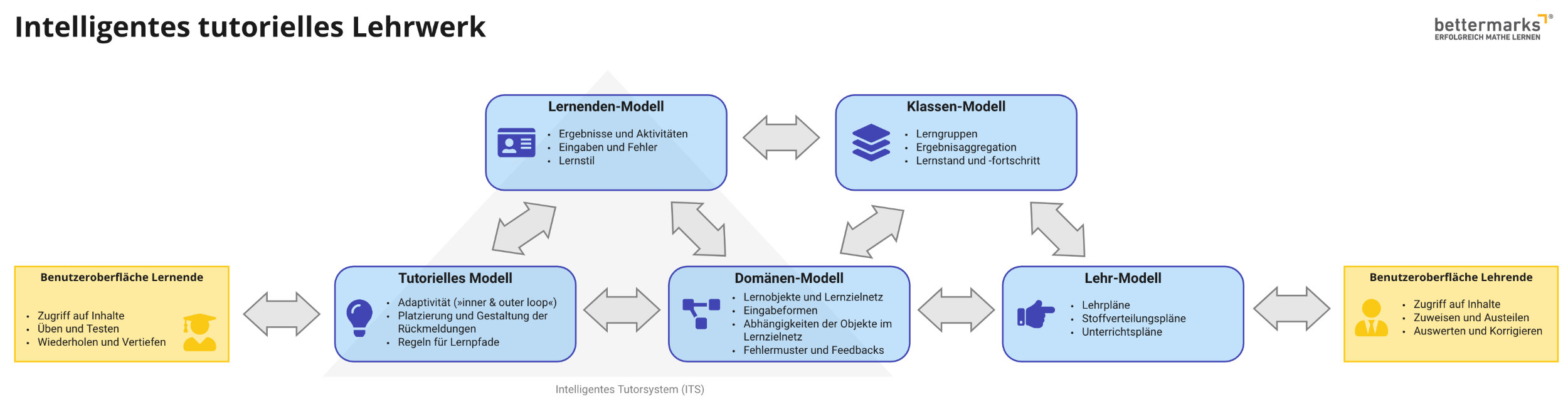
Basis für künstliche Intelligenz sind die Daten eines intelligenten Tutorsystems (ITS), das über folgende Datenmodelle verfügt:
- Tutorielles Modell: Aufbau der Lernumgebung für Rückmeldungen, Hilfen und Lernpfade.
- Domänen-Modell: Inhaltlich-didaktisch Wissen, abgelegt in Lernobjekten, deren Abhängigkeiten (Meta-Daten) und Konzeptkarten (Lernzielnetz).
- Lernenden-Modell: Ergebnisse und pseudonymisierte Lerndaten.
Für ein ITS in der Schule sind zwei weitere Modelle notwendig, damit sich das Potential künstlicher Intelligenz voll entfalten kann:
- Klassen-Modell: Aggregierte Daten einer Lerngruppe
- Lehr-Modell: Aufbau der Lehrumgebung zur Unterstützung der Lehrkraft unter Berücksichtigung von Lehrplänen und Lernzielen.
Vorwärtsgerichtete Lernpfade: »Feed Forward«
Anhand einer Verknüpfung von Ergebnisdaten (aus dem Lernenden-Modell) und der Beziehung von Inhalten (aus dem Domänen-Modell) können wir im bettermarks-System heute bereits Lernergebnisse vorhersagen. Mit Algorithmen eines Recommender-Systems lässt sich die Wahrscheinlichkeit für noch nicht bekannte Lernobjekte ermitteln. Einzige Voraussetzung ist eine gewisse Mindestaktivität. Ein Beispiel: Es steht das Addieren von Brüchen an. Anhand vorheriger Ergebnisdaten und dem Vergleich mit ähnlichen Lernprofilen, lässt sich mit 98%iger Wahrscheinlichkeit sagen, dass Max nur 27% richtige Eingaben machen wird. Max' Frust wäre vorprogrammiert! Eine künstliche Intelligenz erkennt dies und schlägt Inhalte vor, die bei den benötigten Grundvorstellungen ansetzen. Das System würde Vorschläge machen, bevor etwas Lernschädliches passiert: das »Feed Forward«. Max scheitert nicht frustriert am Addieren von Brüchen, sondern übt zunächst, wie Brüche auf einen gemeinsamen Nenner gebracht werden.
Beispiel: New Classrooms
Das adaptive Lernsystem »bettermarks« wird im Kontext des personalisierten Lernens bereits erfolgreich in den USA von der gemeinnützigen Organisation New Classrooms genutzt. Am Beispiel einer New Yorker Schule ist die Rolle der Lehrperson die eines Lernbegleiters bzw. einer Lernbegleiterin. Entsprechend ihres individuellen Lernlevels erhalten die Lernenden automatisch passende Lerninhalte und bestimmen ihren eigenen Lernfortschritt.
Im Gegensatz zum beschriebenen Beispiel von »New Classrooms«, spielt der Klassenverband im deutschen Schulsystem eine zentrale Rolle. Lernen ist ein sozialer Prozess, moderiert durch die Lehrkraft. Eine künstliche Intelligenz kann den Lehr- und Lernprozess nur unterstützen, wenn dies im Sinne der Lehrkraft passiert. Daher ist bei vorwärtsgerichteten Lernpfaden Vorsicht geboten! Führen wir das Beispiel mit Max fort: Das Addieren ungleichnamiger Brüche funktioniert inzwischen problemlos. Die KI empfiehlt anschließend das Addieren gemischter Zahlen. Max würde sich furchtbar langweiligen, wenn die gemischten Zahlen in der nächsten Mathestunde eingeführt werden würden. Im schlimmsten Fall führt Max' Unterforderung zum Stören des Unterrichts.
Das Potential von »Feed Forward« auf den Lerneffekt ist groß, vor allem in Form eines digitalen Werkzeuges der Lehrkraft. Das Erreichen der Lernziele liegt in der Verantwortung der Lehrkraft und ist nicht Aufgabe der Technologie.
Intelligentes Üben
Ein weiterer Anwendungsfall für KI in der Schule ist das intelligente oder auch »produktive Üben«. Im Beispiel des »Feed Forwards« haben wir bereits die Über- bzw. Unterforderung von Lernenden betrachtet. Mit »Scaffolding« (also integrierten Hilfen und Rückmeldungen) werden Lernende mit Schwierigkeiten bereits beim Üben unterstützt. Aufgabenstellungen, die sich dem Lernfortschritt anpassen, können Unterforderung vermeiden. Oder positiv formuliert: Das automatische Überspringen von Aufgaben und der Einschub reflektierender Fragen kann leistungsstarke Schülerinnen und Schüler fördern.
So könnten Kinder, die sicher multiplizieren können, Aufgaben zugesteuert bekommen, bei denen es um das Erkennen von Rechenregeln oder -mustern geht.
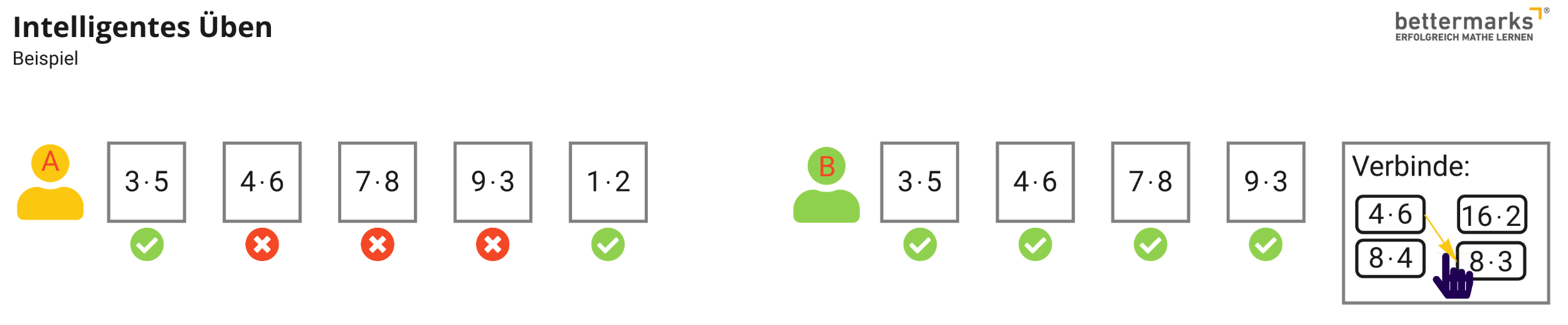
Grundvorstellungen festigen mit neuronaler Lernhistorie
In der Mathematik bauen Themen aufeinander auf. Prozentrechnung ohne Bruchrechnung, Zinseszins ohne Zins: Das wird schwierig. Umso wichtiger sind solide Grundvorstellungen. Sonst werden Wissenslücken schnell zu Wissensgräben. Bereits heute können Lehrkräfte mit Übungen zum Vorwissen die für ein neues Thema benötigten Grundkenntnisse überprüfen. Schülerinnen und Schüler können daraufhin individuell an ihren Wissenslücken arbeiten und Lehrkräfte kennen den Wiederholungsbedarf.
Die Lernhistorie kann auch als longitudinale Betrachtung von Lernergebnissen verstanden werden. Hier kann eine KI erkennen, welche Grundvorstellung wie fest in welcher Darstellungsform verankert ist – und helfen. Nehmen wir ein Beispiel aus der Bruchrechnung: Kann ein Kind keine Brüche erweitern, fehlt vielleicht die abstrakte Vorstellung für diesen Rechenprozess. Jedoch würde eine ikonische Darstellung wahrscheinlich nicht helfen, wenn es bereits Probleme auf der konkreten, also der enaktiven Ebene gibt. Eine KI könnte berechnen, welche Darstellungsform die höchste Wahrscheinlichkeit hat, einen Aha-Moment auszulösen. Auch unter Berücksichtigung des sprachlichen Niveaus. Die KI wählt passend zum Leistungsstand des Kindes eine Erklärung aus.

Die KI ist darauf spezialisiert, noch mehr Aha-Momente zu erzeugen. Ihr Lernstoff: maschinell verarbeitbare Fehlvorstellungen.
Evidenzbasierte Curriculum-Entwicklung
Die anonymisierten Lerndaten aller Schulkinder eines Bundeslandes wären sicherlich ein Quell der Erkenntnis in der Fachdidaktik. Ist das Verständnis für Flächen größer, wenn der Würfel bereits behandelt wurde? Welchen Einfluss haben Änderungen im Lehrplan auf den Erwerb prozess-orientierter Kompetenzen? Diese Fragen (und viele weitere) ließen sich mit hinreichend großen Datenmengen beantworten. Veränderungen im Lehrplan und deren Einfluss auf den Lernerfolg ließen sich selbst auf Ebene spezifischer Lernziele messen.
Künstliche Intelligenz (im ITS) als digitale Assistentin der Lehrkraft
Wird die Lehrkraft durch Roboter mit künstlicher Intelligenz ersetzt? Nein, diese Schreckensvision bleibt Science-Fiction. Empathie, Didaktik und Pädagogik bleiben menschliche Kernkompetenzen. Vielmehr bringt der Einsatz künstlicher Intelligenz das Potential der Zeitersparnis für die Lehrkraft. Zeit, die für die Binnendifferenzierung, tief gehende Unterrichtsgespräche und die soziale Interaktion dringend benötigt wird.
Eine künstliche Intelligenz kann die Lehrerinnen und Lehrer bei Routinearbeiten unterstützen. Zeitliche Entlastung bei Korrekturen, Auswertungen und das Finden von Inhalten, die zum aktuellen Lernstand passen. Die KI wird zur digitalen Assistentin und kann Vorschläge zu Inhalt, Form und Methode machen, von denen insbesondere Quereinsteiger und Lehrpersonal, das fachfremd unterrichtet, profitieren können.
Schülerinnen und Schüler bekommen beim Üben direkte Rückmeldungen, die dafür sorgen, dass sich Fehlvorstellungen nicht verfestigen. Interaktive Tafelbilder können Zusammenhänge klarer erkennbar machen und damit ein tieferes Verständnis fördern. Grundvorstellungen bauen sich auf. Gleichzeitig liefert die KI der Lehrkraft neue Impulse und Ideen für Unterrichtsgespräche, so dass Kommunizieren, Argumentieren und Modellieren stärker in den Vordergrund rücken können.
Rebecca und Richard DuFour formulierten mit dem Titel ihres Buches »Raising the Bar and Closing the Gap« den Anspruch des Schulsystems treffend: Die Messlatte höher legen, die Lücke schließen. Bessere Lernergebnisse, weniger Leistungsgefälle. Mehr Chancengleichheit. Ein intelligentes Tutorsystem ist die Grundlage, künstliche Intelligenz der Verstärker.



Hochspannendes Thema! Der Link zu den "intelligenten Tutorsystemen" lässt sich bei mir nicht öffnen...?
Danke für das Feedback. Der Link funktioniert bei mir: https://de.bettermarks.com/intelligente-tutorensysteme-mint/